1 Einführung¶
Note
Lernziele und Inhalte diese Kapitels
Sie bekommen einen organisatorischen Überblick.
Sie lernen die wichtigsten Begriffe rund um EEBDA.
Sie lernen, wie die Fallstudien aufgebaut sind und wie diese ablaufen werden.
Sie bekommen eine kurze Einführung in die Programmiersprache Python und die Programmierumgebung Jupyter.
1.1 Präambel¶
Willkommen im Kurs EEBDA (Evidenzbasierte Entscheidungen auf Grundlage von Big Data Analytics). Unter Big Data versteht man (in vielerlei Hinsicht) große, zum Teil unstrukturierte Datensätze, die aus verschiedensten Quellen stammen können. Die Nutzung von Big Data erlaubt es Unternehmen, durch die gewonnenen, umfassenden Erkenntnisse bessere Entscheidungen zu treffen sowie besser steuern und kontrollieren zu können. Die betriebswirtschaftliche Lehrinnovation EEBDA soll Sie über Funktionsweisen, Einsatzmöglichkeiten und Herausforderungen von Big Data-Analysen informieren und Sie in Form von selbstgesteuertem, wissenschaftlichem Lernen zum verantwortlichen Umgang mit Big Data-Analysen befähigen. Sie lernen Standardtechnologien der Big Data-Analyse domänenspezifisch (d.h. in jedem beteiligten Spezialgebiet) einzusetzen und Lösungsansätze für Fallstudien zu erarbeiten. Sie sollen somit für den Einsatz dieser Techniken im betrieblichen Umfeld und auch zur (Weiter-)Entwicklung neuer Geschäftsmodelle in diesem Bereich befähigt werden.
Eine Besonderheit von EEBDA ist, dass der Kurs auf neun Wochen komprimiert wird.
1.2 Formaler Aufbau des Kurses¶
Sie finden in diesen Unterlagen verschiedene Hinweisboxen:
Note
Diese Box kennzeichnet Inhalte, welche im Curriculum mancher Kursteilnehmer fehlen könnten und deren Wiederholung zu empfehlen ist. Zu Beginn eines Kapitels gibt diese Box einen Überblick über die Lernziele und Inhalte des jeweiligen Kapitels.
To Do
Diese Box kennzeichnet zu erledigende Aufgaben, welche auch kurs- und prüfungsrelevant sind.
Important
Diese Box kennzeichnet wichtige Aspekte des jeweiligen Themas. Zu Beginn eines Kapitels gibt diese Box einen Überblick über die Inhalte des Kapitels, die als bekannt vorausgesetzt werden.
Tip
Diese Box kennzeichnet einen allgemeinen Hinweis.
Attention
Diese Box kennzeichnet zu beantwortende Kontrollfragen, um das Verständnis der Lerninhalte zu vertiefen.
1.3 Projektpartner und Kontaktpersonen¶
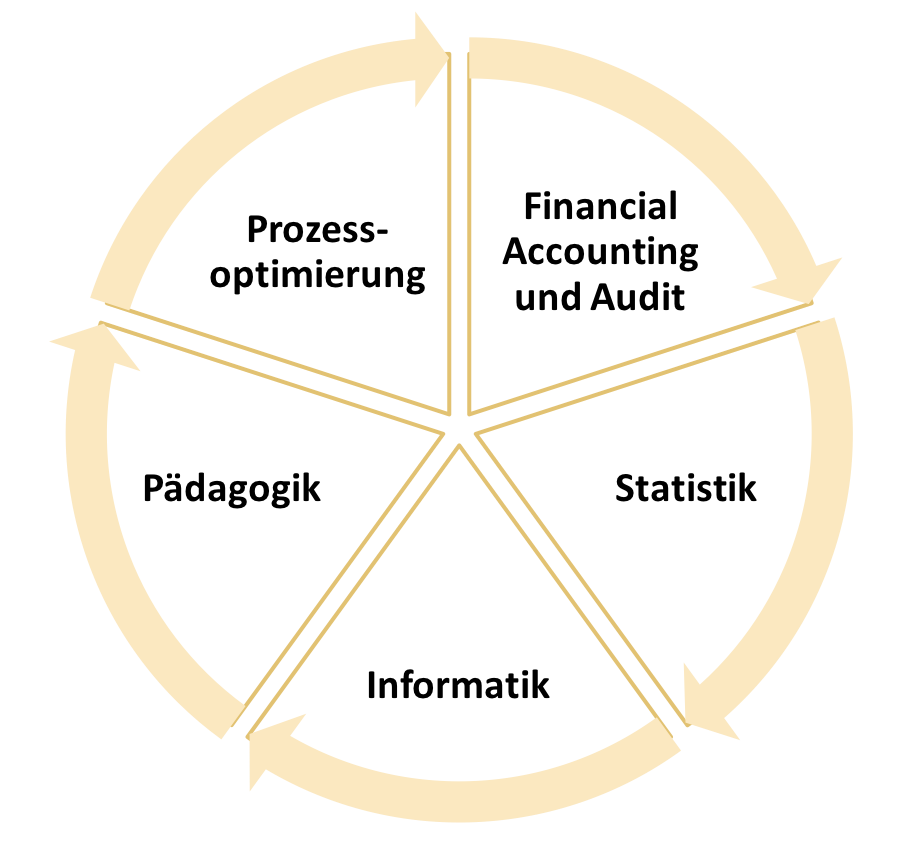
Der Kurs EEBDA ist ein interdisziplinäres Modul in deren Entwicklung Kompetenzen aus 5 Hochschulen vereinigt wurden.
Fig. 1 Alle an EEBDA beteiligten Hochschulen¶
Die Entwicklung von EEBDA wurde vom Ministerium für Wissenschaft und Kunst im Rahmen der Digitalisierungsinitiative Bayern Digital gefördert. Eine Besonderheit von EEBDA ist die hohe Interdisziplinarität. In Zukunft wird es notwendiger denn je sein, sich mit anderen Fächern zu vernetzen und mit Experten aus unterschiedlichen Disziplinen auszutauschen.Um ein passendes Modul zum Thema Big Data Analytics für Wirtschaftswissenschaftler zu entwickeln, wurde für EEBDA ein Team aus fünf Hochschulen zusammengestellt.
Wir verbinden Wissen und Kompetenzen aus fünf verschiedenen Disziplinen:
Die Ansprechpartner für administrative Fragen an den Hochschulen sind:
Hochschule |
Ansprechpartner |
|
|---|---|---|
TU München |
Prof. Dr. Jürgen Ernstberger |
ernstberger@tum.de |
Universität Magdeburg |
Dr. Dominik Fischer |
dfischer@ovgu.de |
Universität Passau |
Prof. Dr. Harry Haupt |
statistik@uni-passau.de |
Universität Passau |
Prof. Dr. Markus Diller |
markus.diller@uni-passau.de |
Universität Passau |
PD Dr. Joachim Schnurbus |
joachim.schnurbus@uni-passau.de |
Universität Passau |
Svenia Behm |
svenia.behm@uni-passau.de |
Universität Passau |
Daniel Ehm |
daniel.ehm@uni-passau.de |
TH Deggendorf |
Prof. Dr. Georg Herde |
georg.herde@th-deg.de |
HAW Landshut |
Prof. Dr. Johannes Busse |
busse@haw-landshut.de |
FH Würzburg-Schweinfurt |
Prof. Dr. Kurt Schwindl |
kurt.schwindl@fhws.de |
Darüber hinaus hat Prof. Dr. Markus Grottke von der AKAD University maßgeblich zum Entwurf dieses Moduls beigetragen.
Für inhaltliche oder technische Fragen nutzen Sie bitte das dafür vorgesehene Q&A-Forum im ILIAS der Uni Passau.
1.4 Administratives¶
Zunächst bekommen Sie einen Überblick über die wichtigsten organisatorischen und inhaltlichen Punkte. Neben den Lernzielen wollen wir Ihnen den innovativen Aufbau des Moduls beschreiben. Außerdem finden Sie in diesem Abschnitt die wichtigsten Informationen zu den geforderten Prüfungsleistungen.
1.4.1 Lernziele¶
Nach Abschluss dieses Moduls sollen Sie in der Lage sein,
Big Data-Analysen hinsichtlich ihrer Eigenschaften den traditionellen betriebswirtschaftlichen Theorien/Entscheidungen/Methoden gegenüberzustellen (insbesondere hinsichtlich Datenerstellung, -verarbeitung, -speicherung, -aufbereitung).
(Einsatz-)Möglichkeiten von Big Data für Wirtschaftswissenschaftler zu evaluieren.
Grundlegende Methoden der Datenbeschaffung, -aufbereitung und -auswertung anzuwenden.
Herausforderungen beim Einsatz von Big Data (z.B. Datenschutz, Datensicherheit, ethische Erwägungen usw.) zu bewerten.
Entwicklungen und Trends von Big Data Analytics (BDA) rechtzeitig zu erkennen und für Ihre spätere Tätigkeit oder für eine Unternehmensgründung zu nutzen.
Tip
Bitte beachten Sie: Im Vordergrund unserer Lehre steht, dass Sie lernen Domänenwissen aus verschiedenen Disziplinen zu verknüpfen. Sie sollen dabei die mathematisch/statistischen Grundlagen nicht nur anwenden, sondern auch verstehen können. Erst dann können Sie kreative Lösungen zu Problemen rund um Big Data und Digitalisierung finden. Dies unterscheidet EEBDA von den üblichen Grundlagen- und Einführungskursen.
1.4.2 Ablauf und Umfang des Moduls¶
Auftakt des Moduls ist eine virtuell abgehaltene Auftaktveranstaltung (Webinar). Parallel erhalten Sie Zugriff auf die elektronischen Lerninhalte, welche in Form von interaktiven Skripten vorliegen sowie Zugriff auf ein Datencenter, in dem die kursspezifischen Datensätze vorgehalten werden. Zudem können Sie auf der E-Learning-Plattform vorgehaltene Video-Tutorials zum Einsatz von Python (siehe Abschnitt 1.8 Arbeiten mit Python und Jupyter) einsehen, um Kernkompetenzen für Datenanalyseprozesse zu erwerben.
In den begleitenden Fallstudien werden die grundlegenden Arbeitsschritte der Datenaufbereitung/-verarbeitung/-analyse, die bei BDA anfallen, gelehrt. Hierzu werden regelmäßig Webinare abgehalten, um die zentralen Schritte nachvollziehbar zu erläutern und Ihnen die Möglichkeit zu geben, Ihre Fragen zum aktuellen Thema zu äußern. Für die fallstudienspezifischen Datenanalysen greifen Sie auf die Programmiersprache Python zurück, um diverse Datensätze mit Hilfe der beschriebenen Verfahren auszuwerten und Ihre Ergebnisse zu visualisieren. Die Fallstudien bestehen jeweils aus folgenden Elementen:
Ökonomische Theorie/Fragestellungen
Datenaufbereitung und explorative Datenanalyse
Zielgerichtete Datenverarbeitung (Modellschätzung und Analyse)
Interpretation der Ergebnisse im Hinblick auf 1.
Je nach Fallstudie werden einzelne Punkte betont und der Schwierigkeitsgrad wird über das Semester hinweg ansteigen. Bei Punkt 4. werden Gefahren der Analysen, z.B. Scheinkausalitäten oder mit den Analysen verbundene ethische Aspekte usw. diskutiert und Online-Angebote über die Lernplattformen zur Verfügung gestellt. Dies ermöglicht den Lehrenden, spezifische, aktuelle Schwerpunkte in diesem sich schnell entwickelnden Themengebiet setzen zu können. Am Ende des Kurses erfolgt eine fragebogengestützte Selbst-Evaluation, die den Erwerb der IT-Grundkompetenzen im Rahmen der Big Data-Analyse messbar machen soll.
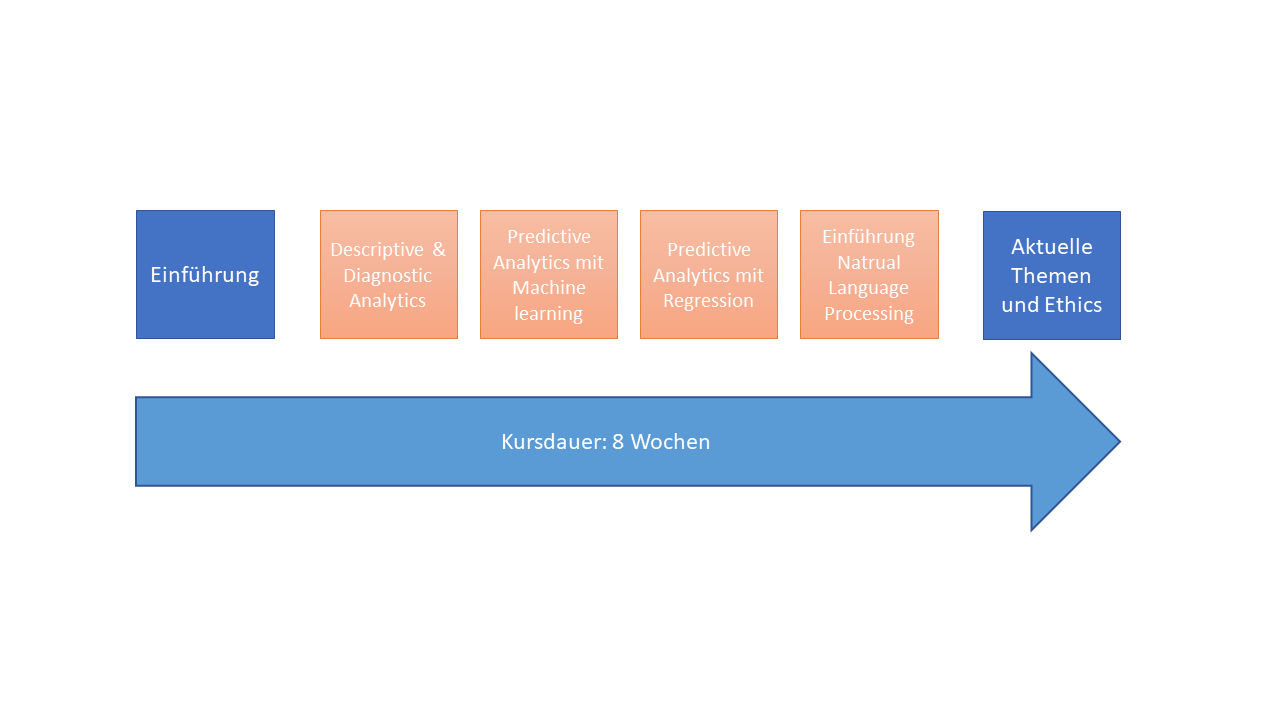
Fig. 2 Der Kurs EEBDA wird in acht bis neun Wochen durchgeführt und besteht aus vier Fallstudien.¶
Die Fallstudien bestehen aus jeweils 5 unterschiedlichen Gliederungspunkten. Je Woche werden 1,5x90 Minuten berechnet (inklusive Erarbeitung des theoretischen Wissens, Videos und Übungsaufgaben). In dieser Zeit werden alle Unterrichtsinhalte wie Recherche, Erarbeiten des theoretischen Wissens, Videolektionen und die eigentliche Übung miteinberechnet. Das Modul ist für einen Gesamtarbeitsaufwand von 150 Arbeitsstunden konzipiert. Da je ECTS-Punkt ein zu leistender Arbeitsaufwand von 25-30 Zeitstunden verbunden sein soll, kann der Kurs als 5- oder 6-ECTS-Kurs angerechnet werden. Somit wird der EEBDA-Kurs mit 6 ECTS angerechnet, es sei denn, die Hochschule lässt nur 5-ECTS-Veranstaltungen zu.
Alle Webinare sind über die entsprechenden Kapitel in Ilias abrufbar.
Important
Beispielhafter Lernablauf: Wie auch in Präsenzveranstaltungen empfehlen wir Ihnen den vorgesehenen Lehrablauf zu berücksichtigen. Gerade der Umgang mit der Programmiersprache Python erfordert etwas Einarbeitungszeit. Außerdem benötigt es Zeit, die Fallbeispiele nachzuvollziehen und die Übungsaufgaben zu lösen.
Da das Lösen der Kontrollfragen und Programmieraufgaben zu einem tiefen Verständnis des Wissens führt, ist dies essentiell für eine gute Prüfungsleistung.
1.4.3 Prüfungsleistungen¶
Am Ende des Moduls müssen Sie eine 60-minütige Klausur ablegen. Diese wird voraussichtlich in Passau und München stattfinden (Je nach Nachfrage können andere Hochschulen als Prüfungsstandorte in Frage kommen). Nähere Informationen zur Anmeldung werden frühzeitig per E-Mail bekannt gegegeben.
1.5 Die wichtigsten Aspekte rund um Big Data Analytics¶
In diesem Kapitel sollen Sie mit den wichtigsten Begriffen im Bereich BDA vertraut gemacht werden. Es wird zudem erklärt, welche besonderen Herausforderungen bei BDA Projekten auftreten und wie Sie diese adressieren können.
1.5.1 Von Daten zu Weisheit¶
Daten alleine sind noch nicht viel wert. In diesem Kurs lernen Sie, wie es möglich ist, aus Daten Nutzen zu generieren. Die sogenannte Data-Information-Knowledege-Wisdom Hierarchie (DIKW) von [Ackoff, 1989] ist ein verbreitetes Modell, um die genannten Begriffe zu beschreiben [siehe dazu auch [Rowley, 2007]]. Abbildung Fig. 3 zeigt den schematischen Aufbau, wobei die einzelnen Begriffe wie folgt abgegrenzt werden können:
Data/Daten selbst stellen kein Wissen dar.
Unter Information versteht man verarbeitete Daten, die einen Nutzen haben. Diese liefern Antworten zu wer-, was-, wo- und wann-Fragen.
Knowledge umfasst im Sinne der Informationsverarbeitung angewandte Daten und Informationen und liefert Antworten zu wie-Fragen.
Wisdom versucht zu beantworten, warum etwas passiert.
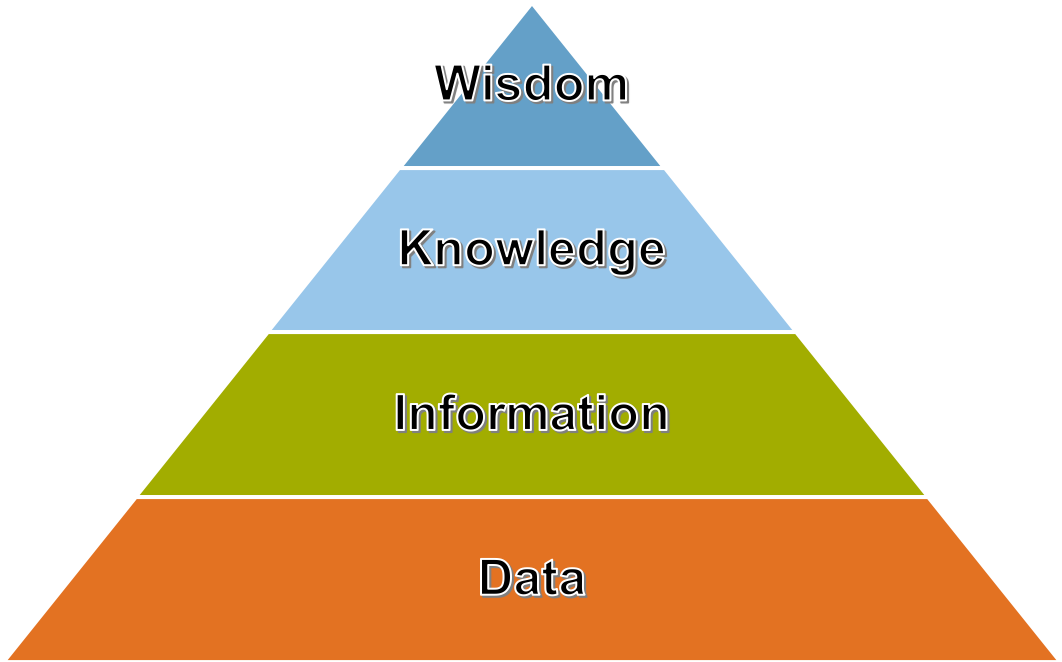
Fig. 3 DIKW Hierarchie nach [Ackoff, 1989]¶
1.5.2 Das Buzzword Big Data¶
Big Data ist in aller Munde, aber eine einheitliche Definition ist schwer auszumachen. Von Big Data wird gesprochen, wenn eine oder mehrere der folgenden Eigenschaften auf die Daten zutrifft:
Volume
Velocity
Variety
Veracity
Value
Näher werden diese Eigenschaften im folgenden Video erklärt:
Videolektion zu Big Data: siehe ILIAS Mediacast
Big Data Anwendungen haben sicherlich schon einen festen Platz in Ihrem Alltag, z.B. basiert die Navigation anhand der Live-Verkehrslage auf den Standortdaten einer großen Zahl von Verkehrsteilnehmer, die Empfehlung neuer Musik oder Filme auf Streamingplattformen basiert auf Ihrem Konsumverhalten, und auch die Wetterprognosen beruhen auf Big Data.
1.5.3 Big Data Analytics¶
Big Data Analytics (BDA) fasst mehrere Unterkategorien zusammen. Je nach Fragestellung und Ziel des BDA Projektes gibt es unterschiedliche Methoden und Herangehensweisen. In diesem Kurs werden Sie primär Descriptive Analytics und Predictive Analytics kennenlernen. An der Zielsetzung eines BDA-Projektes lässt sich erkennen, welche Methodik anzuwenden ist. Dabei ist relevant, ob Sie durch Datenanalyse Informationen aus den Daten gewinnen, komplexe Sachverhalte verstehen oder ob Sie z.B. durch künstliche Intelligenz Entscheidungen treffen und auf Basis dieser handeln wollen.
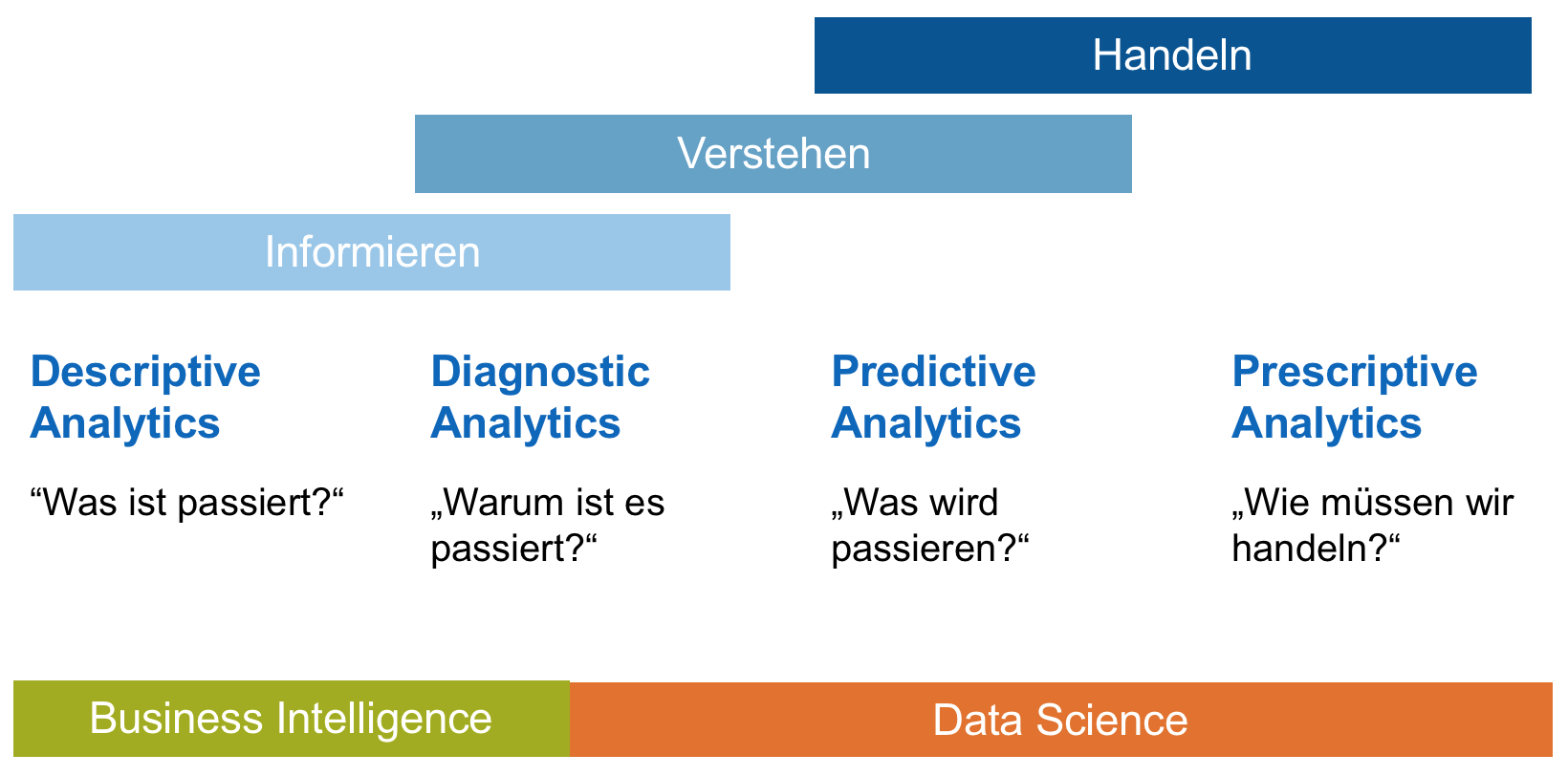
Fig. 4 Analytische Methoden lassen sich in vier Bereiche gliedern. Aus [Wernicke, 2017]¶
Descriptive Analytics wird dazu genutzt, zu beschreiben, welche Informationen in den Daten stecken, und zu verstehen, wie die Daten eine reale Situation repräsentieren.
Diagnostic Analytics wird dazu genutzt, gewisse Sachverhalte tiefer zu verstehen. Mittels statistischer Methoden, z.B. der Suche nach Korrelationen in den Daten, und auch Data Mining Methoden können Muster in den Daten erkannt werden, welche dann auf bestimmte Sachverhalte zurückgeführt werden können.
Predictive Analytics wird dazu genutzt, zukünftige Ereignisse anhand vergangener Daten vorauszusagen, und ist wohl das typischste Anwendungsfeld von Big Data Analytics. Darunter fallen beispielsweise auch Empfehlungssysteme.
Prescriptive Analytics wird dazu genutzt, neue Lösungswege für vorhandene, oft für den Menschen zu komplexe Probleme zu finden. Beispielsweise können Algorithmen genutzt werden, um einen neuen Flugzeugflügel zu konstruieren.
1.5.4 Strukturierte, semistrukturierte und unstrukturierte Datentypen¶
Daten werden von Menschen oder Maschinen generiert und werden dann digital abgelegt. Je nachdem, ob eine E-Mail, eine Bestellliste oder ein Video gespeichert werden soll, unterscheidet sich auch der Datentyp. Die grundlegenden Datentypen sind die strukturierten Daten, die unstrukturierten Daten und die semi-strukturierten Daten (siehe Abbildung Fig. 5).
Strukturierte Daten folgen immer einem festgelegten Datenmodell oder Schema und werden auch oft in tabellarischer Form gespeichert. Oft werden strukturierte Daten in ERP- oder CRM-Systemen generiert. Beispiele sind hier Banktransaktionen, Rechnungen und Kundendaten.
Unstrukturierte Daten entsprechen keinem Datenschema. Es wird geschätzt, dass etwa 80 Prozent der digitalen Daten in unstrukturierter Form vorliegen. Typische unstrukturierte Daten sind Fließtexte, Videos, Bilder und Audioaufnahmen. Technisch gesehen haben diese Daten einen festgelegten Aufbau, doch dass diese Daten unstrukturiert sind bezieht sich auf den tatsächliche Inhalt der Daten, also was auf dem Bild zu sehen ist oder welche Information im Fließtext steht.
Semistrukturierte Daten besitzen auf einem höheren Level eine festgelegte Form. Ein HTML-Dokument (eine Webseite) hat beispielsweise eine standardisierte Struktur und festgelegte Elemente, doch der eigentliche Inhalt ist frei gestaltbar.

Fig. 5 von links oben: Beispiele strukturierter, semistrukturierter und unstrukturierter Daten¶
1.5.5 Warum sind Sie im Zeitalter der Digitalisierung?¶
Machine Learning gibt es schon seit den sechziger Jahren. Auch die ersten Konzepte rund um künstliche Intelligenz wurden bereits damals diskutiert. Der bekannteste Forscher in diese Richtung war wohl Alan Turing.
Tip
Zu empfehlen ist hierzu der Aufsatz: A. M. Turing (1950) Computing Machinery and Intelligence. Mind 49: 433-460.
Ein wichtiger Aspekt ist, dass Rechenleistung immer günstiger wird und einfacher verfügbar ist. Beispielsweise lassen sich über Cloud-Computing-Anbieter wie Amazon, Microsoft und Google innerhalb weniger Minuten ganze Server-Cluster (Computer, die parallel an einer Aufgabe arbeiten können) mieten. Wie im vorherigen Abschnitt 1.5.3 Big Data Analytics erwähnt, sind wir in unserer Zeit mit unvorstellbar großen Datenmengen konfrontiert, welche zudem durch die fortschreitende Vernetzung immer häufiger digital abrufbar sind. Die Kombination aus diesen drei Aspekten (vgl. Abbildung Fig. 6) erlaubt es uns, neues Wissen zu gewinnen. Hierbei können Sie entweder bisher versteckte komplexe Zusammenhänge erkennen oder aber auch in komplexen Daten einfache Muster aufdecken.

Fig. 6 Die Kombination aus Big Data, Effizienten Algorithmen sowie günstigen und jederzeit verfügbaren Rechnerkapazitäten erlaubt uns Big Data Analytics, angelehnt an [Wernicke, 2017]¶
Note
Folgende Beispiel spiegeln wider, wie komplexe Zusammenhänge oder einfache Muster erkennbar sind:
Eine einfache Methode zur Entscheidungsunterstützung bei einem akuten Herzinfarktrisiko mittels Entscheidungsbäumen: Green, Lee, and David R. Mehr. “What alters physicians’ decisions to admit to the coronary care unit?.” Journal of Family Practice 45.3 (1997): 219-226.
Evolutionäre Algorithmen entwerfen komplexe Antennen: Hornby, Gregory, et al. “Automated antenna design with evolutionary algorithms”
1.5.6 Neue Karrieren werden entstehen¶
Es sind nicht immer die ausgeklügeltsten Algorithmen, die besten Daten oder die leistungsfähigsten Rechner, die über den Erfolg oder Misserfolg eines BDA-Projekts entscheiden. Entscheidend sind hier auch qualitative Fähigkeiten, wie
… theoretische Zusammenhänge zu formulieren.
… adäquate Methoden einzusetzen.
… Ergebnisse mit Bezug zur vorherigen Theorie zu interpretieren.
Die blinden Männer und der Elefant (vgl. Abbildung Fig. 7) ist ein bekanntes Gleichnis aus Asien, welches erklärt, dass es viele verschiedene Perspektiven auf die Wirklichkeit gibt.

Fig. 7 Sie sollen lernen, das große Ganze zu sehen. (Cartoon von G. Renee Guzlas in [Himmelfarb et al., 2002]¶
Je nachdem, welchen Blickwinkel man einnimmt, ändert sich die scheinbare Wahrheit. Dies impliziert, dass das große Ganze nur erkennbar ist, wenn alle Perspektiven kombiniert werden. Im Bezug auf BDA bedeutet das, dass Wissen und Fähigkeiten aus unterschiedlichen Bereichen zu kombinieren sind, um ein BDA-Projekt erfolgreich durchführen zu können.
Tip
And so these men of Indostan disputed loud and long, each in his own opinion exceeding stiff and strong, though each was partly in the right, and all were in the wrong! — John Godfrey Saxe
Die wichtigsten Fähigkeiten für eine Karriere in BDA sind somit wie folgt:
Schlüsselqualifikationen:
Business Understanding
IT und Infrastruktur
Korrektes Anwenden von Methoden und Algorithmen
Transferqualifikationen:
Kommunikation und Auftreten
Präsentation
Projektmanagement
Soft Skills:
Wissens-Management
Beziehungsaufbau und -pflege
Team-Management
Eine Einzelperson kann ein BDA Projekt in der Regel nicht alleine durchführen (vgl. Abbildung Fig. 8), sondern benötigt dafür ein gut strukturiertes und breit aufgestelltes Team.
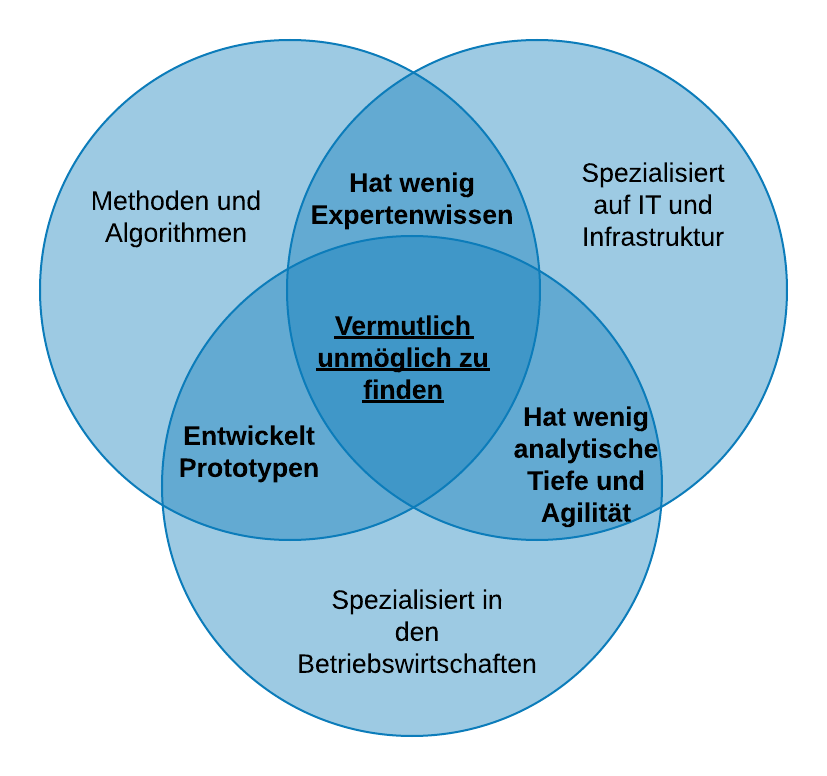
Fig. 8 BDA Projekte können nicht alleine gestemmt werden, angelehnt an [Wernicke, 2017]¶
To Do
Folgender Artikel weist nochmal auf die eigentlichen Herausforderung im digitalen Zeitalter hin:
Digital Transformation Is Not About Technology im Harvard Business Review Irvin
Attention
Erörtern Sie die Antworten auf folgende Fragen:
Was ist Big Data?
Welche Fähigkeiten muss ein BDA-Team besitzen?
Was ist unter Prescriptive Analytics zu verstehen? Geben Sie ein Beispiel.
1.5.7 Statistical modeling versus machine learning¶
Sowohl statistische Modellbildung (statistical modeling) als auch maschinelles Lernen (machine learning) sind wichtige Teilgebiete von Data Science, verfolgen jedoch eine unterschiedliche Zielsetzung. Statisical modeling kann als Teilgebiet der Mathematik und machine learning als Teilgebiet der Computerwissenschaften aufgefasst werden. In statistical modeling werden Problemstellungen typischerweise durch mathematische Gleichungen formalisiert sowie Modellannahmen definiert. Der Fokus liegt auf der Modellschätzung und deren Inferenz. Machine learning hingegen umfasst eine Klasse von effizienten Rechenalgorithmen, die ein Modell auf Basis von Trainingsdaten lernen, wobei im Vergleich zu statistical modeling Modellannahmen kaum beachtet werden. Der Fokus liegt üblicherweise auf der Optimierung der Vorhersageperformance, die auf Basis von Testdaten ermittelt wird. Auch wenn es heutzutage durch diverse Softwarepakete möglich ist ohne fundierte Statistikkenntnisse maschinelle Lernalgorithmen anzuwenden, basieren diese Algorithmen auf mathematisch-statistischen Konzepten. Somit sind statistical modeling und machine learning nicht als zwei trennbare voneinander unabhängige Ansätze zu verstehen, sondern vielmehr, insbesondere im Zeitalter der Digitalisierung, als komplementäre Teilgebiete von Data Science. Unter dem Begriff statistical learning wird versucht, beiden Herangehensweisen Rechnung zu tragen, indem man der algorithmischen Betrachtungsweise der Methoden zwar verbunden bleibt, aber sich auch Gedanken um die zugrundeliegenden Annahmen und statistischen Eigenschaften macht.
1.5.8 R versus Python¶
Ähnlich zur Diskussion „statistical modeling versus machine learning“ sieht es mit der verwendeten Software und Programmiersprache aus. Kurzgesagt verwendet die Statistik und Medizin-Community eher R, wohingegen die Informatik-Community eher auf Python zurückgreift. Beide sind extrem empfehlenswert. Da wir langjährige Expertise mit Python haben, verwenden wir diese Programmiersprache in diesem Kurs, man könnte aber alle Berechnungen auch mit R vollziehen.
1.5.9 Der Zusammenhang zwischen künstlicher Intelligenz und Machine Learning¶
Es fällt auf, dass die Begriffe Machine Learning (ML) und künstliche Intelligenz (KI) fast schon inflationär benutzt werden, besonders im Zusammenhang mit Big Data. Auf den Punkt gebracht ist KI ein eher breiteres Konzept, welches Maschinen beschreibt, die dazu fähig sind, komplexe Aufgaben und Probleme in einer intelligenten Art und Weise zu lösen. ML wäre hier eine zeitgemäße Anwendung von KI mit der zugrundeliegenden Idee, den Maschinen lediglich den Zugriff auf Daten zu geben um sie dann damit lernen zu lassen.
Zum Thema KI sollte noch erwähnt werden, dass zwischen allgemeiner und angewandter/spezifischer KI unterschieden werden kann. Wir kennen hauptsächlich nur spezifische KI, also KI, welche auf ein sehr spezielles Problem zugeschnitten ist. Diskutiert wird immer öfter auch allgemeine KI, also KI, welche der Intelligenz eines Menschen ähnelt oder sogar uns ebenbürtig ist. Die Idee hinter allgemeiner KI ist zudem viel älter als das maschinelle Lernen selbst. Bereits die antiken Griechen erzählten von einer Kreatur aus Bronze (Talos), welche die Insel Kreta beschützte. Auch die Romanfiguren der Golem (1915) oder Frankensteins Monster (1818) lassen sich mit KI in Verbindung bringen. Während spezifische KI ein nützliches und mächtiges Werkzeug ist, könnte eine allgemeine KI das Ende der Menschheit, wie wir sie kennen, einläuten. Mehr dazu in folgendem Vortrag: YouTube: Vortrag über Minds in Machines
1.6 Big Data Analytics Projekte in der Praxis¶
Während es hauptsächliche große Meilensteine der künstlichen Intelligenz in die Schlagzeilen schaffen, sollen zwei Beispiele Einblicke in alltägliche Datenanalyseprozesse geben:
1.6.1 Digitale Wagenreihung der Deutschen Bahn¶
Bei täglich 44.000 Zügen und 7,5 Millionen Fahrgästen können auch schon kleine Digitalisierungsmaßnahmen eine große “Big Data-Herausforderung” für die Deutsche Bahn sein. Ein Fallbeispiel der Deutschen Bahn AG (vgl. [Prof. Dr. Bendedikt Elser, 2018]) zeigt, wie schwierig es ist, eine einfache Idee in die Realität umzusetzen. Folgendes Problem ist gegeben: ICEs besitzen eine feste Wagenreihung, zum Beispiel Wagen 10 bis Wagen 24. Sitzplatzreservierungen sind dann mitunter an den jeweiligen Wagon gebunden. Nun ist es manchmal so, dass die am Bahnhof ausgehängte Wagenreihung (z.B. Wagen 22 an Abschnitt E) nicht mit der tatsächlichen Wagenreihung des Zuges übereinstimmt. Dies liegt an Ausfällen von Zügen, Streckensperrungen oder Umleitungen. Der Lokführer ist nicht dazu verpflichtet, die richtige Wagenreihung durchzugeben und automatisierte Prozesse gibt es bis dato nicht. Ein Pilotprojekt sollte dieses Problem lösen.
Wider Erwarten ist es nicht möglich, auf GPS-Daten des Zuges zurückzugreifen, da auch ICE’s im Dienst sind, die mehrere Jahrzehnte alt sind und keinen GPS-Empfänger besitzen. Außerdem würde jegliche bauliche Veränderung an den Zügen zum Verlieren der Betriebserlaubnis führen. Die Lösung beinhaltete nun die Analyse der aktuellen Verkehrsdaten. Im Verkehrsleitstand ist bekannt, in welchem Streckenabschnitt sich der jeweilige Zug befindet. Ist nun auch bekannt, mit welcher Wagenreihung der Zug gestartet ist, kann die zukünftige Wagenreihung berechnet und gleichzeitig Umleitungen/Sperrungen in Echtzeit berücksichtigt werden. Die vorhergesagte Wagenreihung kann dann kontinuierlich mit den Bahnhofsanzeigen und der DB Navigator App synchronisiert werden, ohne manuelle Interventionen zu benötigen.
Diese kleine Studie zeigt, dass es in traditionellen Unternehmen nicht immer einfach ist, alte Strukturen und Technologien aufzubrechen und zu optimieren. Trotzdem ist es oft möglich, vorhandene Daten zu verwenden um Lösungen für neue Probleme zu finden. Hierzu ist jedoch Domänenwissen essentiell.
1.6.2 Data Engineering: Sammeln, Speichern und Verarbeiten großer Datenmengen¶
Moderne PKWs besitzen eine Vielzahl an Sensoren und technischen Aufzeichnungen, welche das individuelle Fahr- und Nutzerverhalten dokumentieren. Außerdem ist es immer öfter möglich, auf Anwendungen von Drittanbietern zurückzugreifen, z.B. Microsoft Office, Amazon, Spotify. Daten können dabei helfen, die Dienste zu optimieren oder neue Dienste zu empfehlen.
In einer Fahrzeugflotte eines bayrischen Automobilherstellers sammeln sich so aktuell 500 Millionen Beobachtungen (verschiedene Datenpunkte) pro Tag (vgl. [Dr. Nora Vollmers, Andreas Berghammer, 2018]). Dies kann der gewählte Radiosender oder eine Änderung der Klimakontrolle sein. Ein Big-Data-Datenbanksystem (z.B. Apache HBASE oder HIVE) wird hier eingesetzt, um die Daten zentral zu sammeln. Physikalisch sind die Daten jedoch immer auf mehrere dutzend Datenbanken abgelegt, um die nötige Rechen- und Speicherleistung zu gewährleisten. Zusammen mit der Parallellisierung der Arbeitsprozesse können so das Einlesen, Verarbeiten und Speichern von 500 Millionen Beobachtung innerhalb von 30 Minuten durchgeführt werden. Dabei sind 200 PCs mit insgesamt 35 Terrabyte (~3.500 Gigabyte) im Einsatz. Erst der resultierende Datalake ermöglicht es Big Data Analysen auszuführen, z.B. durch das Aftersales, Controlling oder Marketing. All diese Schritte, das Sammeln, Speichern und Verarbeiten großer Datenmengen sind Teilgebiete des Data Engineerings.
1.7 Aufbau der Fallstudien durch ein Prozessmodell¶
If you don’t know where you are going, any road will get you there. – Lewis Carroll
Das Modul vermittelt die Vorgehensweise bei BDA-Projekten anhand von Fallstudien. Diese können als praxisnahe BDA-Projekte gesehen werden. Alle Fallstudien greifen auf ein bewährtes Prozessmodell zurück, den CRoss-Industry Standard Process for Data Mining (CRISP-DM).
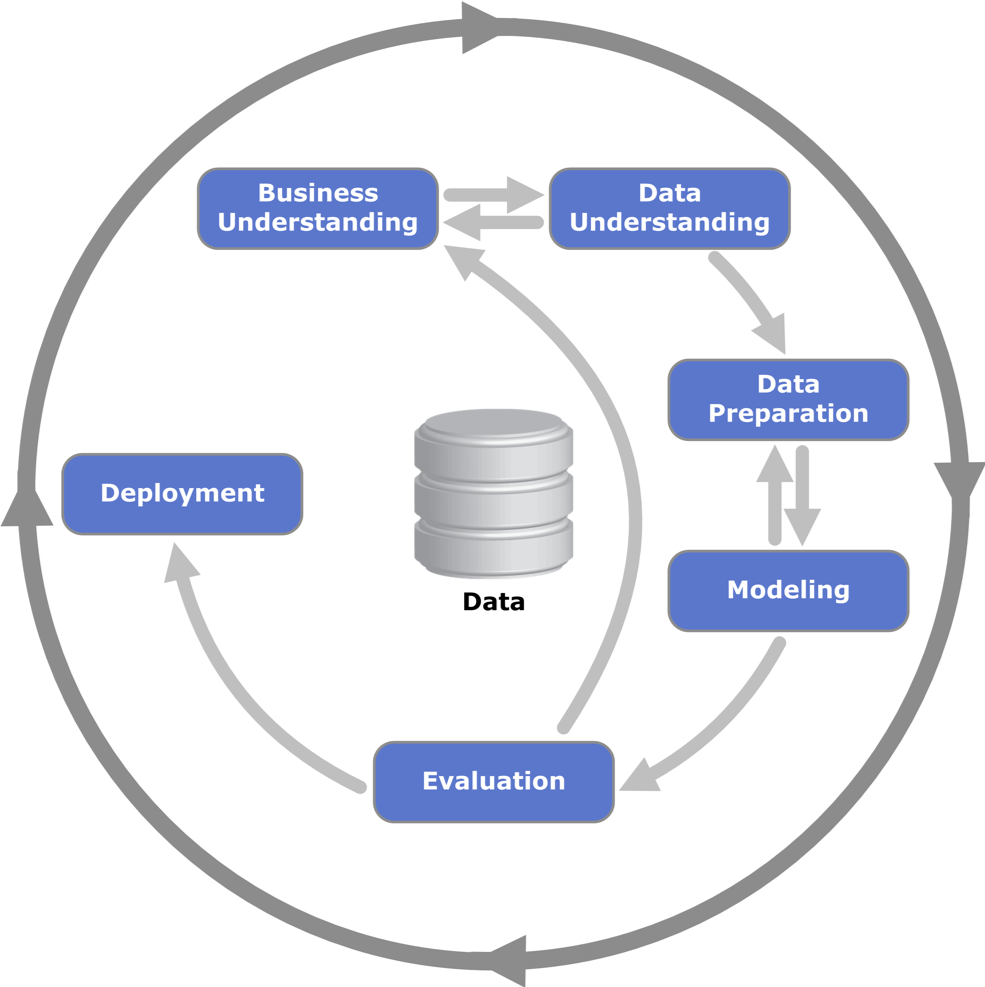
Fig. 9 CRISP-DM 1.0 (Copyright Kenneth Jensen)¶
Das CRISP-DM Modell (vgl. Abbildung Fig. 9) unterscheidet zwischen sechs verschiedenen Prozessphasen, welche in Wechselwirkung stehen. Dabei ist darauf hinzuweisen, dass es zwischen den Prozessschritten verschiedene Feedback-Schleifen gibt, um beispielsweise Projektziele zu revidieren oder um die Datenbasis zu ändern. Auch dieses Modell ist lediglich eine Handlungsempfehlung und muss individuell auf das jeweilige BDA-Projekt zugeschnitten werden. In diesem Kurs dient das Modell primär dazu, die Lehrinhalte zu strukturieren und den Fallstudien einen roten Faden zu geben. Im Folgenden werden die einzelnen Prozessschritte näher erläutert.
1.7.1 Business Understanding¶
Ziel dieses Schritts ist es, die betriebswirtschaftlichen Anforderungen zu identifizieren und sie anschließend in analytische Ziele zu transformieren. Folgende vier Aufgaben werden hier im Allgemeinen durchlaufen:
Definieren des Projektziels (z.B. Entwickeln einer Theorie)
Bewerten des aktuellen Zustands
Entwickeln der analytischen Ziele
Aufstellen des Projektplans
Dieser erste Prozess-Schritt ist oft entscheidend für den Erfolg des Projekts. Werden hier Fehler gemacht, wird dies den weiteren Prozessverlauf maßgeblich beeinflussen.
1.7.2 Data Understanding¶
Als nächstes werden die Rohdaten gesammelt und gesichtet. Rohdaten sind alle Daten die im Unternehmen in Form von Datenbanken, Dokumenten, Sensordaten, Logdateien, etc. vorliegen. Diese erfodern meist einen hohen Aufbereitungsaufwand, um von BDA-Methoden weiterverarbeitet werden zu können. Deshalb muss die Datenbasis auch gezielt ausgewählt werden. Data Understanding umfasst somit folgende Aufgaben:
Sammeln der Daten
Beschreiben der Daten
Erste deskriptive Analyse der Daten
Verifizieren der Datenqualität
Sollte sich in diesem Schritt herausstellen, dass beispielsweise die Datenqualität unzureichend ist (z. B. wegen fehlerhafter Sensoren oder fehlerhafter Eingaben), muss wiederholt das Business Understanding durchlaufen und gegebenenfalls müssen die Projektziele angepasst werden.
1.7.3 Data Preparation¶
In diesem Schritt werden die Daten so aufbereitet, dass sie auch mit den Machine Learning Algorithmen analysierbar sind. In der Realität benötigt dieser Schritt die meiste Zeit. Das Data Preparation umfasst folgende Aufgaben:
Genaue Auswahl der Daten
Säubern der Daten
Formatieren der Daten
Aufbauen eines neuen Datensatzes
Integrieren der Daten in die Modellierungsumgebung (Python, R, etc.)
1.7.4 Modeling¶
Die Daten liegen in einer analysierbaren Form vor. Nun sind noch folgende Schritte zu durchlaufen, um ein (beispielsweise zur Prognose) geeignetes Modell zu entwickeln:
Auswählen der Modellierungsmethode
Aufbauen des Test-Designs
Aufbauen des Modells
Bewerten des Modells
Die Auswahl der Modellierungsmethode ist nicht trivial und grundsätzlich gibt es auch nicht den einen perfekten Algorithmus, welcher immer funktioniert. Die folgenden Flowcharts (siehe Abbildung Fig. 10) sollen Ihnen deshalb einen Anhaltspunkt geben, wann Sie welche Methodik auswählen (trotzdem ist es notwendig verschiedene Modelle gegeneinander zu bewerten):
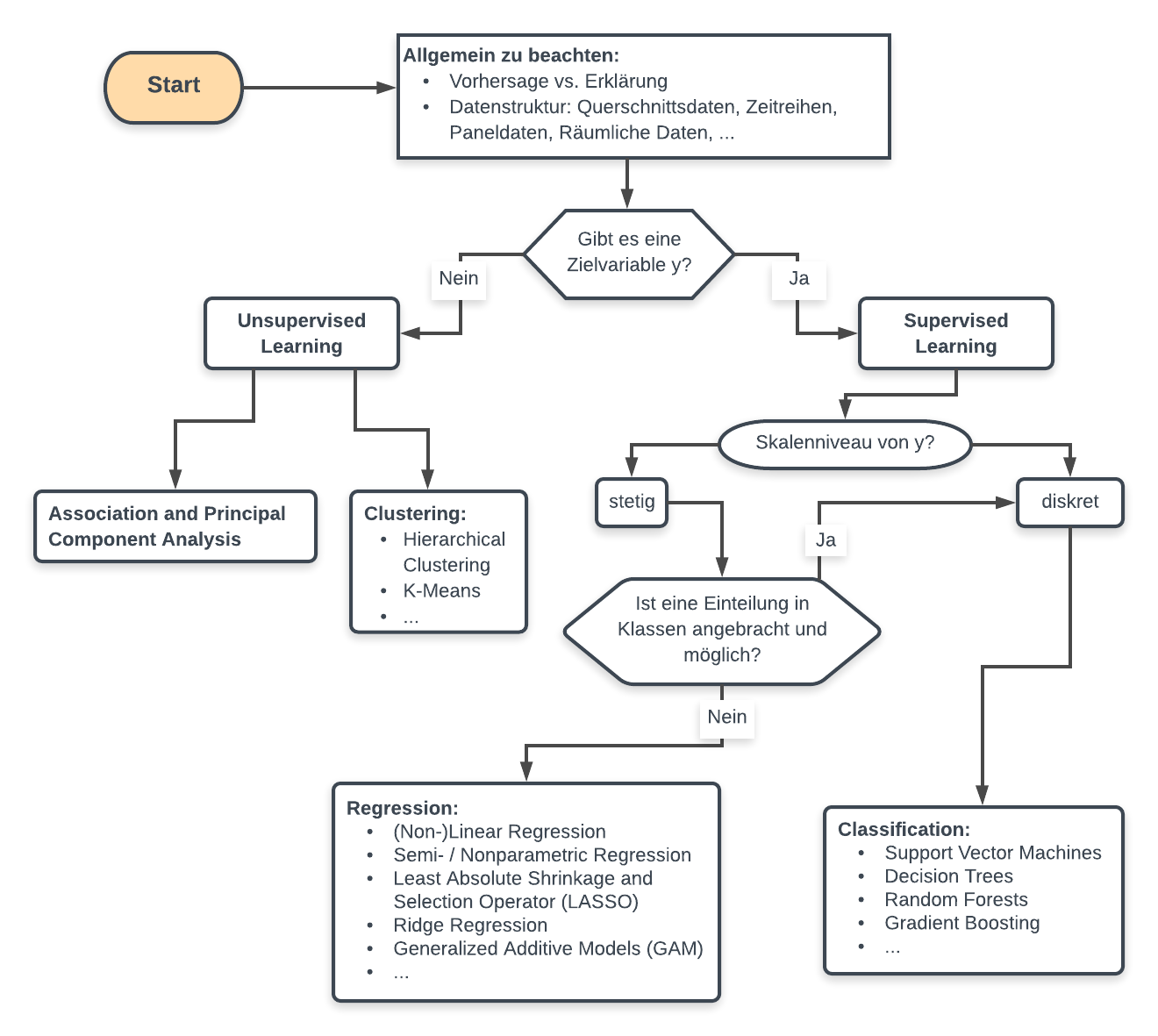
Fig. 10 Flowchart als Hilfestellung zur Auswahl der richtigen Methodik. Die Liste der Methoden ist aufgrund der großen Vielfalt nicht vollständig.¶
Evaluation¶
Bei der Evaluation wird getestet, ob die Ergebnisse des Modells ausreichen, um die zuvor definierten Projektziele zu erreichen. Außerdem muss noch der Entwicklungsprozess überprüft werden, um sicherzugehen, dass alle Compliance-Regeln und Gesetze beachtet wurden. Abschließend definiert man die zukünftigen Schritte für das Ausrollen des Projekts. Die Schritte können wie folgt zusammengefasst werden:
Evaluieren der Ergebnisse
Überprüfen des Prozesses
Bestimmen der zukünftigen Schritte
Deployment¶
Das Modell ist schließlich noch erfolgreich in bestehende Unternehmensprozesse zu implementieren. Hierfür sind folgende Schritte zu berücksichtigen:
Einbinden des Modells in das Unternehmen
Monitoring und Wartung des Modells
Erstellen eines Abschlussberichtes
Abschlussbewertung des Projekts (Fazit, Lessons Learned, …)
Der Schritt Deployment wird in den Fallstudien dieses Kurses ausgeklammert.
To Do
Beschreiben und gliedern Sie ein BDA-Projekt nach dem CRISP-DM. Die oben erwähnten beispiele aus der Automobilbranche oder dem Bahnverkehr können als Beispiele dienen.
Important
Skalierbarkeit der Methoden
Wie im Abschnitt 1.5.7 Statistical modeling versus machine learning erwähnt, beruhen maschinelle Lernalgorithmen auf mathematisch-statistischen Methoden.
Im Rahmen des Kurses EEBDA werden anhand von Fallstudien die grundlegenden Konzepte der statistischen Modellbildung und deren Verwendung in maschinellen Lernalgorithmen vermittelt.
Dabei beziehen sich die behandelten Fallstudien auf relativ kleine Datensätze, sodass die Übersichtlichkeit noch gewährleistet ist.
Jedoch sind die erlernten Konzepte skalierbar und lassen sich auf Datensätze beliebiger Größe übertragen.
1.8 Arbeiten mit Python und Jupyter¶
Damit Sie einen ganzheitlichen Blick auf BDA werfen können, ist es notwendig, dass Sie eigenständig BDA-Modelle entwickeln. Hierbei wird die Programmiersprache Python verwendet. Der große Vorteil von Python ist, dass alle Algorithmen, die in diesem Kurs verwendet werden, bereits als fertige Pakete bereitgestellt werden. Pakete sind Sammlungen von Funktionen/Programmiercode. Pakete werden von der Community entwickelt und über ein Servernetzwerk bereitgestellt. Daraus folgt, dass Sie sich auf die wesentlichen Lerninhalte fokussieren können. Falls Sie fortgeschritten sind, können Sie aber auch selbst Python-Funktionen und -Funktionssammlungen (Pakete) entwickeln. Zudem ist Pyton kostenlos und frei verfügbar, wird durch zahlreiche Hilfeseiten/-blogs unterstützt und wird bereits sehr häufig in der Praxis eingesetzt (Tendenz zunehmend).
Note
Sollten Sie noch nie zuvor mit Python gearbeitet haben bietet sich das folgende kurze Video zum Thema “Was ist Python?” an:
Video
Nebem dem SKript wird Ihnen eine Jupyter-Datei zur Verfügung gestellt, in welcher Ihnen der Code der Fallstudien in aufbereiteter und interaktiver Form bereitgestellt wird und Ihnen somit der Einstieg in Pyton erleichtert werden soll.
Natürlich lässt sich sämmtlicher Code auch in einer geeigneten IDE (Integrierte Entwicklungsumgebung, z.B. Spyder) nachvollziehen.
To Do
Sehen Sie sich die Einführungsvideos zum Kapitel Einführung in Ilias an und stellen Sie sicher, dass Jupyter auf Ihrem PC läuft. Falls Sie ein Apple MacBook mit M1 oder M2 Chip verwenden kann es sein, dass Sie das Skript alternativ, bspw. über Google Colab, laufen lassen müssen. Sehen Sie sich hierfür das Video Using Colab an.
Die ersten Programme in Python werden im nächsten Kapitel, der Fallstudie 1, erklärt.
Important
Eigenständiges Arbeiten
Da wir Sie zum eigenständigen Arbeiten und Lernen anleiten wollen, weisen wir an dieser Stelle darauf hin, dass nicht jeder Codebestandteil erläutert wird.
Falls Hilfe zu Python-Funktionen benötigt wird, können Sie in der Konsole help(Funktionsname) eingeben. Dadurch wird eine kurze Beschreibung der Funktion mit Beispielen (am Ende der Hilfeseite) angezeigt.
Es ist außerdem nicht unsere Absicht, dass die zur Verfügung gestellten Code-Beispiele lediglich kopiert in Python eingefügt und einmalig ausgeführt werden. Wir würden Sie gerne dazu ermutigen, die einzelnen Programmzeilen nachzuvollziehen. Hier einige Vorschläge:
Rufen Sie die Hilfeseiten der Funktionen auf und testen Sie neue Parameter.
Ändern Sie die einzelnen Daten oder Funktionsparameter.
Fügen Sie eigene Code-Kommentare zu Schlüsselstellen ein.
Versuchen Sie, ob eine andere Herangehensweise zum gleichen Ziel führt.
Note
Neben Python gibt es noch viele weitere Werkzeuge um digitale Datenanalysen durchzuführen. Betriebswirtschaftliche Tools sind hier beispielsweise Caseware IDEA oder ACL Analyzer. Grafische Tools finden sich in etlichen der Python-Pakete. Auch um die Programmiersprache R gibt es eine große Machine Learning- und Data Science-Gemeinschaft, die dedizierte Frameworks zur Verfügung stellt.
Zum Teil beziehen wir uns in den Fallstudien auf öffentlich zugängliche Daten. Die Plattform Kaggle dient hier als Quelle und bietet für Interessierte eine Vielzahl an Datensätzen und Data Analytics Wettbewerben: https://www.kaggle.com/
References
- Ack89(1,2)
Russell L Ackoff. From data to wisdom. Journal of applied systems analysis, 16(1):3–9, 1989.
- HSIH02
Jonathan Himmelfarb, Peter Stenvinkel, T. Alp Ikizler, and Raymond M. Hakim. Perspectives in renal medicine: The elephant in uremia: Oxidant stress as a unifying concept of cardiovascular disease in uremia. Kidney International, 62(5):1524–1538, 2002. doi:10.1046/j.1523-1755.2002.00600.x.
- Row07
Jennifer Rowley. The wisdom hierarchy: Representations of the DIKW hierarchy. Journal of Information Science, 33(2):163–180, 2007. doi:10.1177/0165551506070706.
- Wer17(1,2,3)
Sebastian Wernicke. Bauch oder Zahl ? – Entscheidungsfindung in einer datengetriebenen Welt. In LMU Ringvorlesung: Big Data & Data Ethics, number November, 1–43. München, 2017.
- DrNVollmersABerghammer18
Dr. Nora Vollmers, Andreas Berghammer. Nutzerbindung durch verhaltensbasierte Big Data Analyse. WI-Symposium, TH Deggendorf, 2018.
- ProfDrBElser18
Prof. Dr. Bendedikt Elser. Konzeption der digitalen Wagenreihung bei der Deutschen Bahn. WI-Symposium, TH Deggendorf, 2018.